15 Mar 2021
The ports and adapters software architecture pattern is becoming a well-used pattern in a lot of business
applications. It’s quite a good architecture to use, and I am going to explain how to use it, and in situations in
which it could be used for.
What is Ports and Adapters?
The ports and adapters (or hexagonal) architectural pattern aims at creating a loosely coupled application, which can
easily
connect software to their environment by means of ports and adapters. The benefit of doing so makes it easier to
test each layer of the application in isolation.
A port is an interface, ports can be both incoming and outgoing. An adapter is an implementation of a port. Let’s
think of a very typical business application. The application is served from the web and connects to a database.
In the above example the incoming port could be for adding a customer, our adapter is HTTP in which we implement,
this adapter calls some business logic. The application layer may require to pass this information to some other
system in our case a database, so we ensure that we can an adapter for the database, which is outgoing.
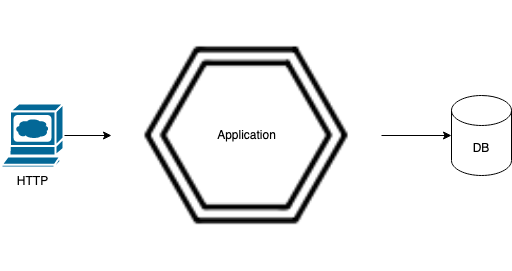
The above looks rather simple, in fact it doesn’t really say anything with respects to how things work. But so far
our diagram demonstrates with description that we have;
- concept of incoming (HTTP) and outgoing (database) adapters (implementations of our port)
- an application layer which drives the application.
The second point is of interest this is where this layered architecture starts to make sense. The application layer
drives what happens, we actually call it a use case. As its used for a typical case, in the above example is adding
a customer, there are many things that might be required when we create a customer such as
- Address record added
- Login details stored
This happens every time we add a customer, perhaps we need a way for another system to add a customer but
the system is internal, and we expose a different mechanism such as a Queue to add them. We could have the
architecture appear like this
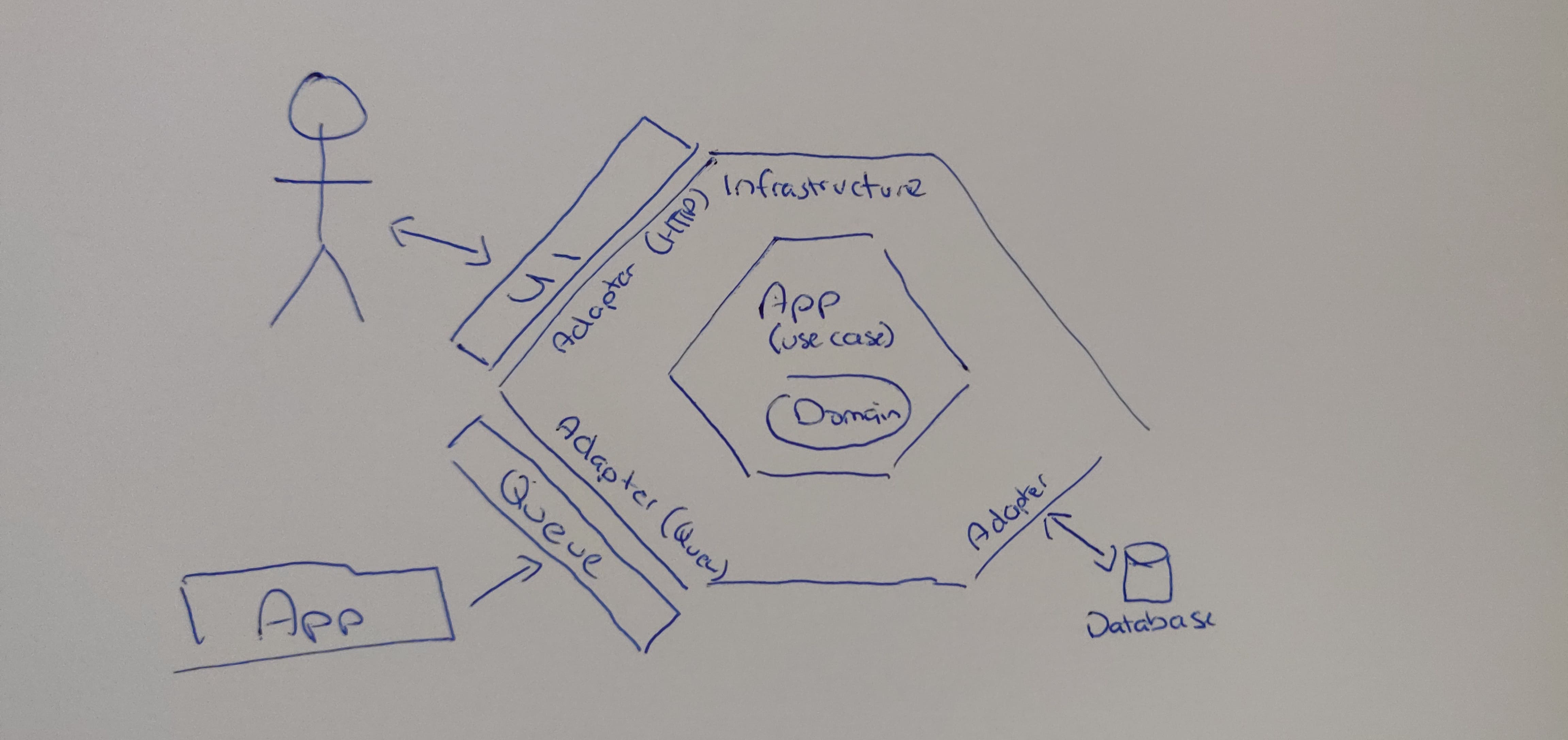
We have several actors here
- A user, which is coming from the UI and sending an HTTP request
- Another service, which sends a message to a Queue
- A use case, which handles the request regardless of the incoming adapter
- A database, which the use case uses
The business logic (the use case), is isolated from the incoming port and uses an interface to determine
the outgoing port, we can concentrate on how it works, we can mock it correctly in our unit tests/integration tests,
and most importantly we can ensure it works regardless of if we change how the request comes in or where the data is
stored.
Learnings
During my time using this pattern I have come across various questions and misconceptions, some which I’ll go
through in my own experience
- Do I need an interface for an incoming port?
- Can a use case reference another use case?
- We are doing DDD, we use the ports and adapters architecture.
Do I need an interface for an incoming port?
During my using of this, I have never created an interface in a language that supports them for incoming ports (or
incoming adapters). There is simply no reason to as the PORT in this case is the interface of the protocol e.g. HTTP.
Interfaces should only be used (if available), where the usage of them will ensure switching out implementation
means changes don’t bubble up into other parts of the system e.g., outgoing adapters where we go from MySQL to a
NoSQL database for storing data.
Can a use case reference another use case?
I have done this, and although I haven’t read it in articles etc. saying you should or shouldn’t, I really see no
reason why it shouldn’t be used.
A good example of this is in an application I am working on currently in which we require authentication information,
this authentication information is required by 2 use cases. If we implement it in both, its possible we at some
point make a mistake, and we have an inconsistency. When we create a use case to do this for us we hide completely
any implementation logic and remove this duplication.
We are doing DDD, we use the ports and adapters architecture.
I have actually heard this a few times, Domain Driven Design or DDD is not just a implementation of the ports and
adapters architecture. This misconception seems to have happened as this pattern is regularly used in projects which
do DDD, it then becomes an assumption that to do DDD you.
When should I use this pattern?
Business applications are a very good candidate for implementing this pattern. Business applications usually need to
evolve over time and various technologies come and go, but hte business logic usually remains the same or at least
changes irrespective of other changes, meaning these changes shouldn’t happen due infrastructure changes.
I have to admit, outside business applications there aren’t a great deal of good cases for using it, so happy to
hear what others have done.
09 Mar 2021
You may often hear that you need to ensure to get the test coverage up, or that only 100% coverage is acceptable. I
am here to say that although there is some truth to this, there is more to it then simply this.
What is code coverage
Let’s firstly discuss what code coverage is.
Code coverage simply put is source code of an application that is “executed” under test. The measurement is taken
from instrumenting code and then creating a percentage of code executed under tests and what is not. Some tools even
give information where code is not executed under test conditions.
As we can measure it we can also break these measurements down to get a good understanding on certain aspects,
commonly known metrics are:
- Statements — An expression to be carried out
- Branches — Usually understood with if/else statements these branch off
- Functions — What percentage of functions have/n’t been tested
- Lines — Each line of source code.
There are of course more, but these are the common ones that I believe most are familiar with to some degree.
Although these metrics are useful to understand, they don’t really tell you a lot. You’ll never go to a meeting
saying our coverage is low overall, but at least our branches have high coverage.
How should you use it?
Code coverage in my opinion is useful for both unit and integration tests, however predominately I use them only for
unit tests as that is where most of the value in automated testing lies.
It should be said, although code coverage is useful, and may give you confidence going forward. It needs to be
understood it is just a metric, you can easily prove that although you have high coverage your defect rate can be
the same without.
The question is how should you use it? Firstly I think to answer this you need to understand your testing strategy,
at least with respects to automation, after all code coverage is part of the automated testing repertoire.
My advice would be to link the coverage to unit and integration, with a strong focus on unit testing. What I mean by
this is if a bug is spotted, the first point should be to write a unit test, not an End-to-End or integration test,
although they maybe required, the unit test is where you demonstrate the failure and perform the fix to prove its
resolved.
Before performing to fix, you could use code coverage as a way to demonstrate the bug was because of lack of tests
executing a certain aspect of code, but this is not always the case.
With that said, I view code coverage simply as a way to build confidence in the team. Confidence to make changes and
ensure that those changes remain isolated, and don’t break other parts of the system, and if they do the tests will
demonstrate this due to covering large enough parts of the code base. To ensure the team has confidence metric
targets should be kept to ensure the system remains at an agreed level of coverage.
A big part to having confidence is ensuring your tests are actually good. Unfortunately good is quite subjective,
but my take on good tests ensure you follow the basic principles of unit testing as well as ensuring your tests are
easy to understand and change.
Another thing to note is that although code coverage does give confidence, the confidence should be realistic, and
thats because code coverage does not guarantee you’ll catch all errors. In fact this is just a limitation on testing
itself, you cannot guarantee 100% errors are caught.
What now?
Code coverage is but one tool to use for tests, and ensuring quality with regards to reducing defects. But like all
tools, it has limitations so understand why you use it. In my view code coverage is simply a way;
- Increase confidence of the system within the team, so changes can be made
- A way to drive an agreed upon coverage of tests within the system to maintain that confidence.
This is circular, that is you keep the coverage high, you ensure confidence in the system is high (or at least good).
Like all things continually review this an ensure what is good previously is good now, or ensure you change to
reflect the changes you face.
01 Mar 2021
For some software engineers the role of software tester, and quality assurance are roles that should go by the
wayside. Most of these software engineers are following the agile methodology to software development, where the
roles are often seen as blurred, or non-existent.
I am writing this article as I recently was interviewing an Engineering Team lead, who stated he saw the role software
tester as a role to still hire for. Unfortunately I never did ask question how he saw the role fitting within a team,
to my loss. It did raise for me the concept of role of software tester and how they can fit within an agile software
team (agile is used loosely here).
I want to make it clear my opinion early on was that with agile software testers role was more or less gone,
I worked with a software tester at one company, unfortunately the role was the old waterfall approach, you do some
work, test it as best you can and the figurative over the fence to the tester. Unfortunately having a single
software tester in a team meant that there was a backlog of stories/tasks to test, which were blocked. This of
course made me think that the role shouldn’t exist, it didn’t fit agile.
Then I joined another company, much larger that would never hire any sort of software tester, the role of
testing fell squarely on the team to handle, and no one had the specailised title of software tester. Which is quite
strange, there were specialists in agile, devops, infrastructure etc, but the role of software tester was just
something you didn’t discuss. My time there saw many errors, which made me reevaluate my opinion on software tester
role.
Software developers are notoriously bad at testing, we think some automated test (if we bother), is
enough to spot issues. This can be the case some time, but others it’s not enough, we usually only think about
testing when we are writing code, or afterwards. Manual testing is usually not something we do unless a Product
owner sits down with us and goes through the story/task with us (and yes I’ve been in this situation).
I am still of the opinion that the traditional software tester role is gone, they cannot be a blocking agent within
the flow of work, but they should become an enabler, a multiplier. The only way to do that is to get software
testers who understand software development. What this means is they can also work on stories/tasks but they are
acutely aware of how changes affect software and what should be tested;
- During story/task creation they’ll enforce strategies that should be followed for testing
- They’ll spot potential hazards early on, and see point 1.
- They are a coach, their role is not software testing, but rather coaching others on testing.
This is not a complete list, but I think point 3 is the strongest point there. They coach software developers on
testing practices both automated, manual and how to think differently. This enables other developers to take an
approach not taken previously, this also makes them a multiplier, they dont need to be the ones just testing,
software developers will do this.
Of course the issue now is
- Getting people to understand the need again and;
- Finding the right software testers who can fulfill this role.
It’s good to know my line of thinking is not quite that unique in this, so hope is there that these people are out
there, as written in “Agile Testing: A Practical Guide for Testers and Agile Teams” by
Lisa Crispin and Janet Gregory.
22 Feb 2021
The pull request (or PR), is often overlooked in part of the deployment process, however it plays a very critical
role in ensuring quality and shared understanding of the overall application. Here are some key aspects from my many
years creating and reviewing pull requests.
Keep them small
Keeping your pull request small makes it easier for the reviewer(s). Think of your reviewers as customers, you want
your customers to buy what you are selling with no obstacles in there path. A PR should be viewed in a similar light.
If you have a large PR, the reviewer will either spend considerable amount of time looking at the PR and thus making
feedback longer for yourself, or worse and quite common to just approve the PR. Both of these should not be our goal
of a PR.
Long feedback loop
I discussed this in a previous article on E2E testing. We always want a shorter
feedback loop to enable flow. Flow is the concept that comes from LEAN. Essentially to enable flow we need to
eliminate waste, long feedback loops is a type of waste that is you are spending considerable amount of time waiting
for feedback to either continue on to the next item, or to react to feedback. This wait time is what we want to
eliminate.
Simply approve
PRs are a teaching tool. I like it when people comment on my pull request it means I have something to learn. Simply
approving my PR tells me that what I have done is acceptable even if it truly isn’t. For anyone that has had the
enjoyment of reviewing a PR that is 1000+ lines, and then seeing it approved signals to others this is acceptable.
Big PRs in my experience usually hide many problems (I myself have caused some), some times this means a blocked
pipeline, or worse the work makes it to production only for a revert to be required or fixes to be drip fed into the
system until resolved.
My advice to those reviewing a large PR. Simply request changes explaining the PR should be broken up. Offer
assistance in doing so also.
Single purpose
This is tied to keeping your PR small. A small PR is usually focused on a single thing e.g., a configuration change,
infrastructure. If your PR has multiple focus points, the PR in my opinion is doing too much and requires more
context from the reviewer to properly go through the requested change.
Ensure commit messages are clear
Commit message should give enough context on what was changed in that commit. Simply stating
Addressed PR feedback
gives later viewers zero context as to what was changed without reviewing the commit and even still this may not be
clear. I learnt to follow a structure of
If applied, this commit will “your commit message here”
By following this format, it will help you write clearer commit messages, which are especially useful for historical
context.
Ensure your commit message is a maximum length of 72 characters. This is obviously quite difficult if you have
multiple changes within the commit, another reason to keep it singularly focussed.
Give your PR context
Commit messages should be short, they should easily fit within the git log message on a single line with no cut off.
This restriction usually means some context may not be as clear as you would like, Github allows a larger message to
accompany the PR commit, ensure you give as much context as necessary, after all you want them to read it.
Constructive feedback
A PR is not a one way street, the reviewer also plays a part in making effective PRs. A PR is not just getting code
into the mainline branch, but it is also a learning tool both for the author of the commit and the reviewer.
- Explain clearly what is wrong with the change.
- Offer suggestions on how to improve
- Ensure your reviews are based on the code.
- If necessary link off to documentation etc. which makes the point clear
For me the 4th point can be a strong way to ensure opinions are removed from the discussion. I find opinions unless
there is some considerable weight behind them (demonstrable rather than authoritative) can get a little out of hand
in certain situations.
Conclusion
This is not an exhaustive list of PR rules, and thats because these main items are things that need to be done first
and the others are really getting into the nuts and bolts of it, and because of that are usually specific to the
organisation as well as languages involved.
Keeping PRs small, with a single focus as well as giving your PR additional context will make it easier to get PRs
approved, allow learning. With constructive feedback a true learning experience should be available to you and your
team.
15 Feb 2021
End-to-End testing (or E2E) is an often used testing practice to get a feeling of how the application works from a
users perspective. Unlike unit and integration testing in the automated testing pyramid they ensure all
functionality is working.
I have implemented and worked with E2E tests for about a decade, and can safely say E2E in
theory are great, in reality they are unfortunately extremely problematic.
Why do developers love E2E tests?
I think this is a bold statement, but let us go with it. E2E tests allow developers to write automated tests, which
give us an impression of whether the system is working or not from a user perspective. They should be run
against production or very production like system to have real confidence. They allow us to write fewer tests in
theory with respects to unit and integration tests.
In short a developer, and even the product team have a sense of accomplishment with E2E due to the fact they are
had done more with less.
What is wrong with E2E?
I have referred to E2E tests as tests from the user perspective or more formally simulating user scenarios. But E2E
is a poor substitute for that. For starters automating user scenarios is not something easily done, without data to
inform decisions e.g., Could you realistically simulate actual user scenarios in which buttons are clicked in
order correctly? With one button you could, 2 you could also but your amount of tests has now doubled, add another
button in again, and the number of tests is starting to get unmanageable. We could look at this from the perspective
of a simple editor.
It fails the primary purpose of testing, but what other areas do E2E fall short for a developer?
- Long feedback loop
- Flaky tests
- Tests are not isolated
- Difficult to setup
Anyone who has done E2E before has run into each of the above issues in some way or another, and they actually slow
the development process down, or more likely simply get dropped. Let’s quickly go over each issue.
Long feedback loop
E2E tests generally walk through a simple user scenario. We may hit one or more areas within a single test e.g., from
a web perspective we may hit several screens to perform the scenario, in which we have hit many backend systems.
Running a single test can take many seconds to typically minutes. This is due to the fact that something usually
needs to be set up (normally a browser), it requires a screen to load, waiting on certain aspects to be available to
perform the scenario.
Due to this time it takes to run, its much slower to get feedback on a problem existing, you now then need to
discover where the problem is. As E2E tests are not isolated to a single unit of work but to a greater system, the
failure could be in any underlying system. For example, it could be the UI itself, the API, the backend system, an
external system. The list goes on, once isolated can you determine how it should be fixed (best done with a unit
test and/or integration test), and re-run the E2E to assure its resolved at the top level.
The big carrot for automated tests is the short feedback loop that is; knowing there is an issue, isolating the
issue, fixing the issue, and proving its fixed.
Flaky tests
Unfortunately E2E tests can be flaky, my examples are all driven from the browser so I cannot speak to other E2E
style tests. We have various frameworks trying to solve this by doing retries such as cypress but even still E2E
tests are flaky, and it can be down to a number of reasons
- UI execution (race conditions, async)
- Tasks in the background system
- Is the environment isolated, could there be a deployment happening?
I could continue on with this list, but I kept it short to make the point. Flaky tests reduce confidence in our
tests and our system. I have seen many developers state it, and fewer practice the preaching. But flaky tests have a
tendency to just get re-run, and oh it works. Unfortunately this gives a false sense of security, which will
eventually hit someone else as a real problem may have actually been uncovered but ignored. The problem here is that
it pushes problems further down the line, making it more difficult to fix later on.
Tests are not isolated
As much as we try E2E tests are very difficult to keep isolated. As mentioned previously our system, which we use for
testing may have a deployment going. But the problem is further escalated from that. To run an E2E test we typically
need some data to be present in the system. This might be when we load the system up, or perhaps we refresh it when
we run the tests. We need that data otherwise its nearly impossible to run E2E tests without huge investment to
make it possible.
What we end up with, is tests that are reliant on other tests due to results of the data present in the system. Not
only do we have a shared fixture (our test data), but that shared fixture has results from previous tests, which
means we have tests interacting with each other, and our fixture data is mutable. It makes it very difficult to run a
test in isolation that is a single test by itself.
There are ways to spot this, but it continues on with it potentially being very difficult to do, not to mention add
time to running our tests. See Long feedback loops.
Difficult to setup
We want to isolate our tests, which means we may need to build additional components to make insertion and removal
of test data in our system easy between E2E test setup, and between the individual tests. You also need to ensure
you have test data available, some times you require a lot of test data to demonstrate certain features like search.
Depending on your system, it may not be possible to allow this, so you need to handle the fact there might be data
from a previous run, all these make writing and setting these tests very difficult.
What should we do?
E2E tests are not something we should shy away from, but being reliant on them as our source of automated test is in
my opinion wrong (or you could get Googles opinion also).
What you should do is
- Make it possible to setup and clean up after tests and full test runs
- Ensure tests are possible to be run in isolation
- Limit the number of tests you write. Only common scenarios should be tested
- Favour unit tests and integration tests
- Remember that manual tests are also possible and should still be done which may bring more value.
Conclusion
E2E tests have their place, but they should be used sparingly. Use E2E tests on areas that are frequently used and
benefit most of automation. Value other automated testing techniques such as unit and integration testing, and
remember that exploratory testing will give you better value than E2E tests.